Disclaimer: This section is a TL;DR of the main article and it’s for you if you’re not interested in reading the whole article. On the other hand, if you want to read the full blog, just scroll down and you’ll see the introduction.
- In his famous book Machine Learning, Tom Mitchell defined ML as “the study of computer algorithms that improve automatically through experience.”
- The algorithm learns automatically in a loop, but humans must establish rules for this learning process.
- When compared to standard statistical modeling, machine learning is time-saving because the data modeler needs to make the improvement her/himself, while ML algorithm uses a lot of data to make accurate decisions.
- Being able to write down the function and final prediction for ML is what differentiates it from artificial intelligence. In AI the function is not known and often impossible to write down in an explicit mathematical way.
Using Machine Learning in Digital Marketing
- It can be used to analyze customer reviews in an eCommerce store. These reviews are a bunch of unordered text files that need to be categorized.
- Another example is social media feeds for sentiment analysis.
- For cluster analysis (to search for subgroups with common baseline patterns).
Artificial Intelligence Defined
- It‘s the science and engineering of making computers behave in ways that until recently we thought required human intelligence.
- When we say AI nowadays, people think of Siri, Alexa and other “intelligent” assistants. These digital assistants can perform some basic tasks for you.
- The term artificial intelligence was first used in 1956 by a group of researchers including Allen Newell and Herbert A. Simon.
Artificial Neural Networks
- These networks try to imitate the human neural networks that exist in our brains. It’s the class of algorithms that model the connections between the neurons.
- Neural networks are popular and widely used in medical research, especially in bioinformatics for DNA sequence prediction, gene expression profiles classification, etc.
Deep Learning Defined
- It’s a specific approach used for building and training neural networks.
- The input data is passed through a series of nonlinearities or nonlinear transformations.
- Deep learning is actually a part of machine learning.
Deep Learning Applied in CRO
- An intelligent chatbot that actually uses AI can help you in a fast and efficient way to provide better customer support or makes the sale process much shorter.
- Ecommerce stores can implement the “people who bought this also bought” feature through product tagging – however, deep learning can provide a much more interesting data set.
The Trap of Personalization
- There is a trap of too much personalization in ads, searches, social media content, etc.
- It is called a “filter bubble” effect or the “echo chamber” described recently by Jiang et al.
Evolutionary Algorithms in Experimentation
- There is much more about AI usage in conversion rate optimization than just chatbots, personalized ads, or profiles.
- There are five main stages in the evolutionary algorithm: (choosing) Population, Evaluation via Fitness Function, Selection, Crossover, and Mutation. In the first step, we choose a population characterized by a particular set of variables (genes).
Conclusion
- Genetic algorithms are a very flexible tool. You can specify more than one fitness function for each segment you want to find a winner in. And each segment can have different fitness function criteria.
Here’s A Longer And More Detailed Version Of The Article.
Can we use Artificial Intelligence (AI) to improve the user experience on a website and thus impact the site’s conversion rate?
It seems that many products try to mention that they use AI as a unique feature that makes them different from other competitors.
However, many AI methods are always confounded with machine learning methods.
What is Machine Learning?
In his famous book Machine Learning, Tom Mitchell defined ML as “the study of computer algorithms that improve automatically through experience.”
The phrase “improve automatically through experience” is a crucial point since that is what we call “learning.” Obviously, “machine” refers to “computer algorithms.”
Who is learning then? We or the algorithm?
The algorithm learns automatically in a loop, but we must establish rules for this learning process. This automatic “learning” is therefore controlled by us, but we do not have to improve the learning models manually.
This means that ML is convenient as compared to standard statistical modeling when a data modeler needs to make the improvement by her/himself. It is definitely time-saving, mainly when the ML algorithm uses a lot of data to make accurate decisions.
What are the examples of the typical machine learning process?
Let’s take an example from the medical field, where ML helps solve many classification problems. ML is used to assess MRI images to decide whether the patient has a disease or not.
The ML algorithm must begin with an initial “learning set.” This is a set of MRIs with a diagnosis made by the physician. The algorithm is “trained” initially through by using the initial learning set. Afterward, the algorithm will classify a “test set” of new images.
The training process is based on exposing the algorithm to a set of images with known diagnosis.
During this phase, the analyst builds a model (a function) to describe the relationship between the image characteristics and the diagnosis outcome. This model specifies the potential image features are the likely candidates for meaningful predictors. The algorithm will test the images to see if it can establish that relationship.
In machine learning, we know the final predictors in the model, and we know what the function is. So you can plug-in the predictors into the model function and obtain the expected outcome (or the probability of that outcome).
Once this function is built and its parameters are estimated, we can check the accuracy of the algorithm prediction. In other words, we can check how well the algorithm is trained. If the algorithm is well written, then it will search for similar patterns in the test and learning sets – and make the classification based on those similarities.
In other words, the algorithm will look for the MRI that is the most similar to the one it is evaluating and assign its class into that MRI. In this example, the algorithm learns only once, unless we give it another training set.
Note on reinforcement learning –
Some algorithms are constantly learning. These are called reinforcement learning. In the reinforcement process, our classification algorithm will look at the accuracy of its own prediction and use it for further learning. How? Penalizing wrong decisions and awarding the good ones.
As you can see, with ML, we know the function and the final predictors – and we typically write down the function in an explicit mathematical way.
That is what differentiates ML from artificial intelligence (AI): in AI, the function is not known and often not possible to be written down in an explicit mathematical way.
Using machine learning (ML) in digital marketing
There are many classification problems in digital marketing where ML can be handy. Let’s take an example of analyzing customer reviews in an ecommerce store. These reviews are a bunch of unordered text files that need to be categorized.
Another example is social media feeds (Facebook, Twitter, etc.) – These are powerful sources of data, that provide a valuable opinion about a given product, brand, website, or a tool. In statistics, analyzing what people share is referred to as Sentiment Analysis, and it was used for many years for survey analysis.
As a result of the large amount of data that social media provides, the demand for Sentiment Analysis increased tremendously in the last few years.
Back in the late nineties, the “big data problem” referred more to science, such as genetics or psychics. Nowadays, the “big data problem” has the face of “Facebook”?.
Of course, there are also other problems that ML can solve apart from classification related problems.
When we do not have the classes defined a priori, we might be interested in finding the groups of similar features.
For example, we do not want to merely classify our visitors to “bought” or “did not buy” – we might want to dig deeper. In this case, ML is used for cluster analysis. ML is used to search for subgroups with common baseline patterns, regardless of any “bought/did not buy” type of response. ML could be used to classify visitors as “likely to buy” or “not likely to buy.” Imagine a visitor coming to your site, and ML tells you that the visitor is likely to buy – what kind of offer do you show them? Do you need to show them any offers?
How about estimating how much a visitor is likely to spend. This is modeled using regression modeling – which is just a linear function that represents the relation between the amount spent by the visitor and a set of predictors. Those predictors can be strictly related to visitor characteristics such as age or the region. Still, there could also be other information included, such as the type of device he/she uses or time (day) of the transaction, etc..
All those models can learn and be automated using ML.
Artificial intelligence
Now that you have become more familiar with machine learning, allow me to introduce you to AI.
According to Andrew Moore,
Artificial intelligence is the science and engineering of making computers behave in ways that, until recently, we thought required human intelligence.
Another definition is:
The simulation of human intelligence processes by machines, especially computer systems
In other words, AI is all that comes naturally to human beings like communication through conversation, drawing conclusions, and making decisions. When we say AI nowadays, people think of Siri, Alexa, and other “intelligent” assistants. These digital assistants can search for some information for you, book a flight for a hairdresser, say a joke, or tell you the weather forecast.
The term “artificial intelligence” was first used in 1956 by a group of researchers, including Allen Newell and Herbert A. Simon.
Since then, the definition of AI changed as more and more developments in the field take place.
What was referred to as AI in the past is not what AI is today.
We notice that more companies claim that they use AI in their products. This was not the case twenty years ago. When IBM developed the famous Deep Blue, many insisted that it was not using artificial intelligence, while it actually did.
Everything has changed after deep learning methods, and neural networks became popular.
Artificial neural networks
Let us start from the neural networks (NN), or we should rather say artificial neural networks. As we might guess, these networks try to mimic the human neural networks that exist in our brains. Therefore, it is the class of algorithms that model the connections between the neurons.
These algorithms are derived from biological systems. They consist of a network of nonlinear information processing elements called “neurons” that are arranged in layers and executed in parallel.
This is called “the topology of a neural network.”
The interconnections between the neurons are the synapse (or weights), just like in our body. We can train them with supervised algorithms. In the supervised training, the network knows the inputs and compares its actual outputs against the expected one.
Kirshtein suggests:
Errors are then propagated back through the network, and the weights that control the network are adjusted based on these errors. This process is repeated until the errors are minimized. It means that the same set of data is processed many times as the weights between the layers of the network are refined during the training of the network. This supervised learning algorithm is often referred to as a back-propagation algorithm
Neural networks are popular and widely used in medical research, especially in bioinformatics for DNA sequence prediction, gene expression profiles classification, and analysis of gene expression patterns.
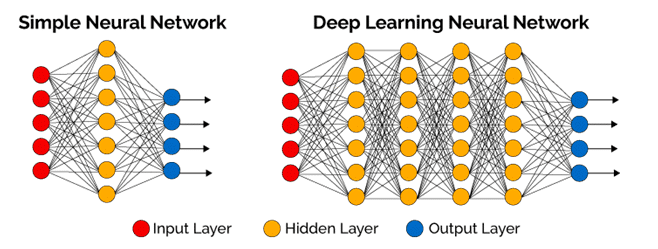
Deep learning
Deep learning is a specific approach used for building and training neural networks.
The input data is passed through a series of nonlinearities or nonlinear transformations.
In contrast, in most modern machine learning algorithms, the input can only go only a few layers of subroutine calls. The key thing here is the word layers.
Following Geoffrey Hinton, Deep learning:
the layers themselves are composed of multiple processing layers to learn the representations of data with multiple levels of abstraction. (…) These layers of features are NOT designed by human engineers: they are learned from data using a general-purpose learning procedure”. Therefore, we cannot control the structure of deep learning architecture. Completely black box.
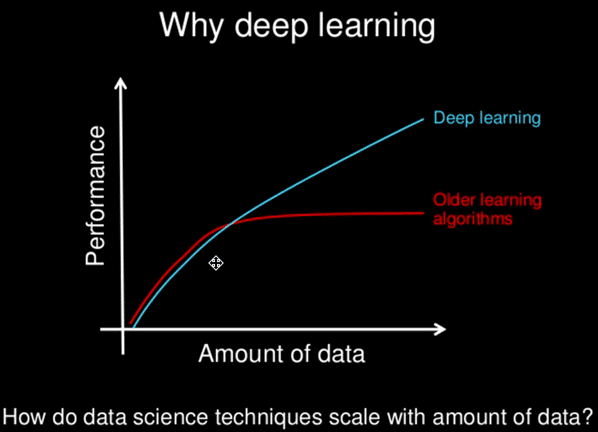
Deep learning is actually a part of ML. Both deep learning and neural networks are not new concepts. They both existed for a long time, but people just didn’t know how to train such networks. During the last 10 years, algorithmic improvements and the advances in hardware allow you to run small deep learning models on your laptop.
The difference in the performance of those algorithms does not get worse as more and more data are given as input, which is the case for the traditional algorithms.
Deep learning in CRO
Let’s come back to the world of CRO and digital marketing. How can deep learning methods be used there?
An intelligent chatbot that actually uses AI can help you in a fast and efficient way to provide better customer support or makes the sale process much shorter.
Another way of using deep learning is through the massive amount of customer data through their personalized profile, personalized search, personalized clicks, and product suggestions. Ecommerce stores can implement “people who bought this also bought” feature through product tagging – however, deep learning can provide a much more interesting data set.
Of course, both of these examples are not new. Chatbots existed long before; the same applies to google translators or digital assistants. But the quality of their performance left much to be desired before using deep learning methods.
Speech and face recognition, image classification, and natural language processing helped these products take really great leaps forward.
Nowadays, everyone claims to use AI, and the word “AI” helps to sell everything. While in reality, they usually use a variant of machine learning technology….
The trap of personalization
There is a trap of too much personalization in ads, searches, social media contents, etc.
It is called a “filter bubble” effect or the “echo chamber” described recently by Jiang et al.
In practice, it means that the user is continuously exposed to the same content defined by his/her own previous choices. That narrows the potential products of interest – and in the long term, will have very adverse effects on future sales.
It is also very annoying for customers because they see the same kind of ads or contents all the time. Their interest is not around only kids all the time just because they ordered the product for kids in the past.
Have you watched a couple of videos on Facebook and noticed that your video feed is full of videos on the same topic?
The term of the “filter bubble” was actually first coined by Pariser. His vision was pretty scary:
Imagine a world where all the news you see is defined by your salary, where you live, and who your friends are. Imagine a world where you never discover new ideas. And where you can’t have secrets.
But there is hope. Jiang et al conclude:
The best remedies against system degeneracy we found are continuous random exploration.
According to the simulation results for the system dynamics, a user has to be continuously exposed to new content/products “at least linearly.”
Evolutionary Algorithms in Experimentation
There is much more about AI usage in conversion rate optimization than just chatbots, personalized ads, or profiles.
The power of science was always in its interdisciplinary character. So, CRO benefits and uses biology concepts such as evolutionary algorithms. These algorithms mimic the Darwinian natural selection process.
There’s nothing better than the mechanism behind our evolution looking for constant improvement so that we are better and better adapted to the changing environmental conditions.
As a result, “good genes” are becoming more prevalent, and “bad genes” are eliminated (or switched off).
The same happens to bad or good algorithms.
This is conducted via the so-called “fitness function,” which plays the role of an assessment criterion. The fittest individuals from a population survive to produce offspring. Their children inherit the parent’s characteristics, and these good features are shared by the next generation. Every generation will be better than the previous one and therefore have a higher chance of surviving. In the end, a generation with the fittest individuals continues to survive.
There are five main stages in the evolutionary algorithm: (choosing) Population, Evaluation via Fitness Function, Selection, Crossover, and Mutation. In the first step, we choose a population characterized by a particular set of variables (genes).
Example: Suppose we want to consider 6 changes in website design.
Think of each gene as a single change in the website design. Genes are coded using binary 0/1 notation (two possible alleles).
In CRO, setting 1 will be a presence of a change in the website, and setting of 0 denotes an absence of that change in the site design. The string of genes is called a chromosome, and these are all the changes we want to consider (or not) in website design.
Therefore the length of a chromosome is the number of all changes in website design we want to test. In our case, the length would be 6.
The gene that is responsible for a single change has a position on the chromosome. The gene has an allele that is either 0 or 1 representing the absence or presence of a change.
A single chromosome is one of the possible solutions to a problem. It is a combination of all changes in the website (present or not). The population is, therefore, a set of those solutions (combinations), a set of chromosomes.
Each individual (chromosome) is evaluated using a fitness function. This function is a criterion that measures how good your solution is. In short, the fitness function is a function we want to maximize. Therefore, it should give low values for bad solutions and high values for good ones.
In a CRO setting, the fitness function could be just a conversion rate in a given time interval.
But we can think of more specific criteria. The fitness function could be a conversion rate in a given time interval only for a particular subpopulation of all traffic etc. Based on the fitness function, each solution gets a fitness score. That score is a probability for the individual to be selected for reproduction.
In the Selection stage, the individuals (combinations with the highest conversion rate) are chosen to be parents for the next generation. That process happens based on the probabilities calculated in the previous step using the fitness scores.
In the crossover stage, the parents’ genetic material mixes:
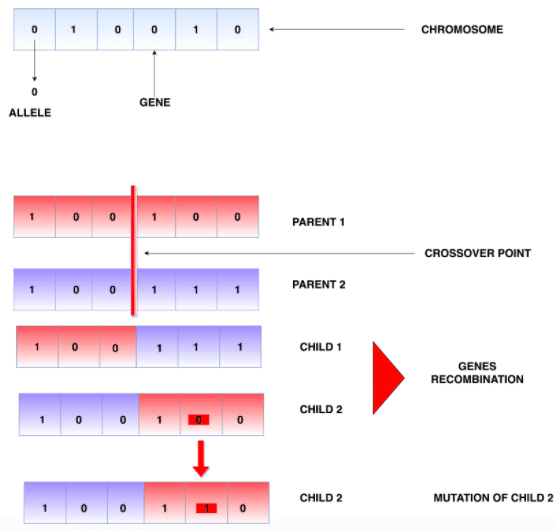
That means that a child inherits some part from one parent and the rest from the other. As a result, new possible solutions are created which have some changes in the website design present and some absent, similarly to their parents.
Finally, in the mutation step, one or single genes might change from 0 to 1 or vice versa in an offspring. That means that with some probability, some changes would be switched off or on in a given combination. The mutation might or might not occur. We control it via the likelihood of mutation parameter.
The population size is fixed. That means that the individual designs (possible solutions) with the worst fitness characteristic die, making the space for the newborn. That means that the combinations with the lowest conversion rates are eliminated. In every iteration, all steps are repeated to obtain a better generation (combinations with a higher conversion rate) than the previous one.
If the next generation is not significantly different from the previous one, the process stops. We say that the algorithm reached convergence, and there is no sense to continue it since the algorithm produced the solution to our problem.
Can we not just simply test all combinations?
In a given example, there are 2^6 all combinations, which is not much (64). That might not be much for larger sites – you will probably need 2,000,000 visitors a month (at 1% conversion rate).
But when we consider more changes on the website, the number of all possible solutions might be huge. For 20 changes, it is 2^20=1048576. The genetic algorithm allows us not to test all of them in a brutal force” manner but searching for the best solution in a more efficient way.
Conclusion: ML or even AI will NOT do our job
Genetic algorithms are a very flexible tool. You can specify more than one fitness function for each segment you want to find a winner in. And each segment can have different fitness function criteria. But even if a genetic algorithm can help us test many combinations of the existing variations of the website, this is our job to formulate those variations (genes). It will not evaluate the genes that are not given or invent a new one. You have to specify the fitness function(s) and final segments.
The power of gene algorithms in disciplines such as image recognition is in its genes specification. Because genes could represent tiny areas of the images such as pixels, we do not need to specify the specific parts of the image to look at, based on the experts’ knowledge (however, that might speed up the algorithm considerably). We might let the algorithm do all the jobs, and it will probably invent some relevant new areas, which were not considered before. To achieve the same effect in CRO, we need to then “pixelate” the problem so that the genes are as tiny changes as possible. Then that algorithm can build the solution out of those bricks pixels
Of course, “there is no free lunch,” and working with only pixels in image recognition leads to very slow convergence. Therefore, people invent the whole method of efficient image segmentation. So each gene is instead not a pixel but a polygon – which can be circles, squares, rectangles, etc. Also, each gene encodes codes the color, position, or size of a polygon.
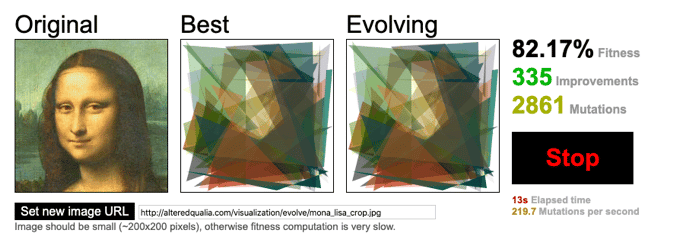
You can read more technical details (and some cool pictures of Mona Lisa 🙂 )

Do we have the same problem in CRO? Very unlikely, unless one wants to test every single word appearing on the website. So there has to be a balance between the number of potential variations to test and the time to get the results. The fact that we have the genetic algorithm now does not mean we need to test “everything.” The AI methods were invented to help experts, not to replace them.